One of the tools we’ve built during Wellcome Data Week was designed to make searching through specific datasets easier
Dan Williams Wellcome Data Week was something we did for the Wellcome Library at the Wellcome Collection. The purpose of Data Week was to check that their digitisation efforts were useful, that humanities researchers and other academics can use and access the data.
Nat Buckley They were trying to discover whether the digitised data is available in the right formats and whether it’s complete and accessible to the people interested in it. They were wondering whether they should provide tools for playing with and exploring the collection. It was important for them to learn from the researchers about their needs and workflows to understand how the data might be used in the future.
Dan For Wellcome it was a chance to see researchers using their collection, whether they can access and explore the information they need. It’s a way of knowing how to plan for the future.
Dan There were a few researchers there who had different questions they wanted to explore using the collection. We split into four different groups. Each group had one developer/designer type person who could help them work through the data and build tools to answer the questions. The aim of the week was to work out if they can answer their questions by using the digitised collection. We both got paired with a different academic. You were with Dr. James Kneale...
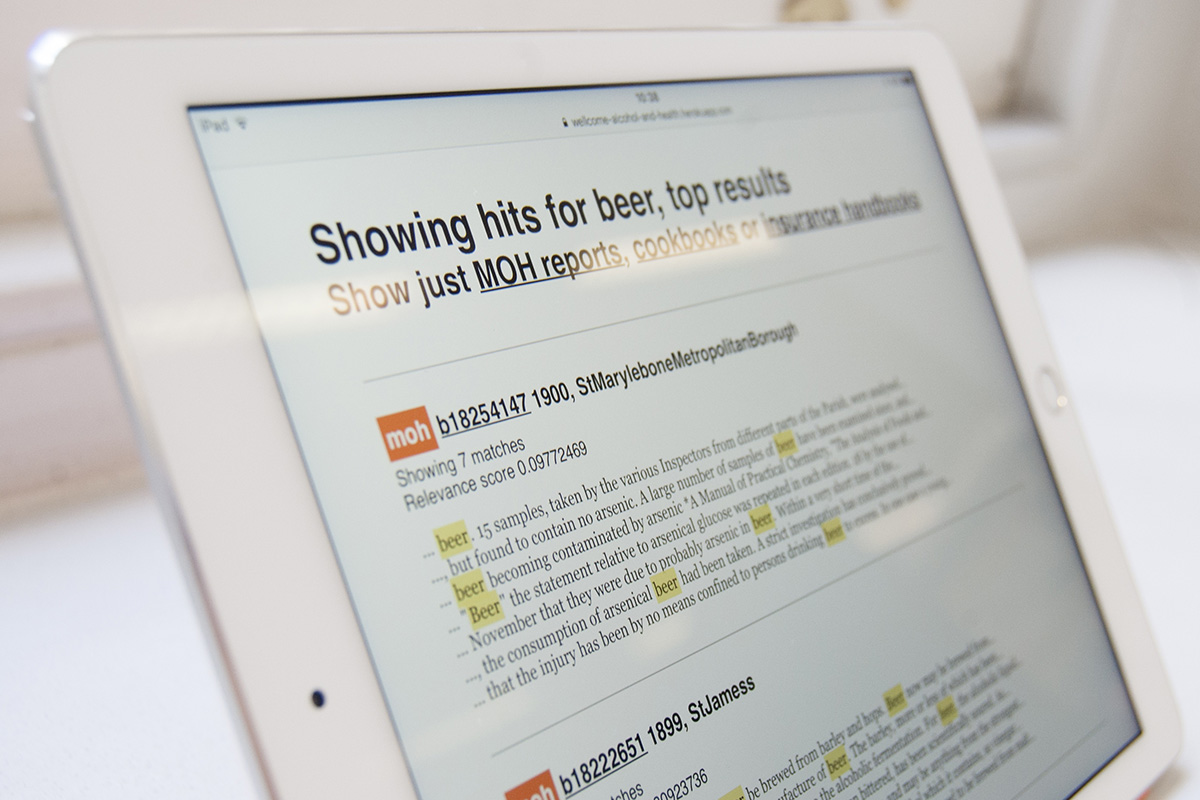
Nat James was interested in how the attitudes to alcohol have been changing over time, and how they were reflected in different kinds of documents. His hypothesis was that Medical Officer of Health reports contained more judgemental or critical language than, for example, cookbooks. He made a guess that cookbooks would treat alcohol as an ingredient and not something medical.
Dan Meanwhile, I was paired with Dr. Sarah Bull who was looking at 19th century sexual health books and the way they all plagiarise each other.
Previously, Sarah was going through texts sentence by sentence, and then searching for each sentence in places like the Internet Archive and Google Books to see which other publications were duplicating it. She identified an initial network of a handful of texts that she thought had copied from each other. The idea was to do this in a more automated fashion, across the whole of the Wellcome Library.
Nat On our team we had Rioghnach Ahern who works at Wellcome and knows the collection really well. She knew how to find and use other online and internal tools to find different kinds of documents. It was her understanding that enabled us to figure out how to approach the problem.
We collected a bunch of terms referring to alcohol in different ways and grouped them into categories reflecting either their critical or more neutral feel. We then ingested thousands of documents into the tool, including cookbooks, health reports and insurance handbooks written by doctors. We then ran searches against them to compare what language they used to talk about alcohol and alcohol related issues.
This process let us discover that cookbooks didn’t necessarily shy away from discussing alcohol in medical or critical context. Mrs. Beeton’s Cookbook mentions liver cirrhosis on one of the first few pages! So the initial hypothesis was already shown to not necessarily hold up.
An interface for exploring the search results across multiple datasets

Dan You built a web interface for the tool which lets you explore those different terms.
Nat It’s an app that lives on the web, so anyone can access it. It ran a bunch of searches, and accumulated the results in a database. It was designed to let James sift through them and identify interesting sources. It was meant as a starting point for further research. He can look through results for each specific term across all documents, or explore each term only within cookbooks or insurance handbooks for example. The links to the collection show the original documents, which can be explored page by page.
Dan What did you use to build it?
Nat I used Elasticsearch, which is a service designed for powering custom searches on your data. It works really well for text documents, and lets you construct very complex queries and run them pretty fast.
It was my first time using Elasticsearch, so I didn’t have a great understanding of how to structure queries to make them as fast as possible, so some ended up being quite slow to begin with. As a team we spent some time writing out the possible queries on a whiteboard, trying to guess what approach could best answer the questions we had.
I was working very fast, and trying to find ways to continually get the rest of the team to give me feedback about the progress. It was important to get something showing on the page as soon as possible, so that the rest of the team could help me figure out what to do next and how to query the datasets. That meant we all had lots to do, instead of me getting siloed and revealing a “finished” thing at the end. I structured my process around that.
Dan Just like your project, we also worked with Elasticsearch. A lot of the week was about accessing the text, getting it into Elasticsearch and processing it. We thought that we could process three- to six hundred books out of the whole collection, but by the end of the week we got it to process six of them.
An interface which highlights sections likely to be copied from other sources

Dan We built a web interface which lets you dive into each book. It highlights any sections of that book that it thinks are highly likely to be similar to sections in other books. You can click on them and see what other sections it thinks are similar to the one you’re looking at, ‘This section of Manhood is very similar to this section of Silent Friend’. It’s very much a tool to speed up the work Sarah was already doing.
You can quickly see that this plagiarism was really commonplace. People were publishing books not because they are accurately conveying information, but for ulterior motives, as a form of marketing or boosting their reputation as a doctor. It’s really fascinating to see these parallels between Victorian book publishing and, say, present day fake news or content marketing.
Nat Our role was as much about providing useful feedback about the process and the collection as it was about making stuff.
Dan Wellcome have an API for the collection, but it isn’t widely documented at the moment. You have to know a little bit about it to be able to use it to grab what you need and have to know how to get to different bits of it. One of the things we learned was that it could be made more accessible to developers by documenting the endpoints in a single place.
Another was that making a better search across the collection could be useful, because the data in there, the documents themselves, are amazing. For each page you have the exact coordinates for that snippet of text in the page, so you can do things like take the image of the page and draw highlights over the words and phrases that you want to draw attention to.
Nat For me it was especially interesting to see how the documents are digitised, and then how different data formats suit different types of exploration. From the technical perspective the digitisation process is fascinating, especially seeing which parts of it have been automated and which parts haven’t.
Dan It’s quite a manual process with a lot of QA and people visually checking that the scan of the document is correct. It is fascinating.
The whole week was a new process for Wellcome. The bringing together of collaborative teams of developers, designers and researchers was a useful thing to try to see what works and what doesn’t work.